[ Blocking unidirectional throughput test
] [TOP]
Blocking stream (unidirectional) throughput test is the
default setting for mpitest. We start testing Gigabit Ethernet and then the
Myrinet:
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -r 5 -o output
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size blocking stream (unidirectional) test
Test result: "output"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output
# MPI communication test -- Wed Jul 14 16:32:53 2004
# Test mode: Fixed-size stream (unidirectional) test
# Hosts: mk3 <----> mk4
# Blocking communication (MPI_Send/MPI_Recv)
# Total data size of each test (Bytes): 515899392
# Message size (Bytes): 1048576
# Iteration : 492
# Test time: 5.000000
# Test repetition: 5
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 822.8124 5.02 0.11 1.59 5.02 0.70 3.00
2 822.7987 5.02 0.09 1.86 5.02 0.83 3.08
3 822.8318 5.02 0.07 1.76 5.02 0.84 2.99
4 822.2579 5.02 0.03 1.87 5.02 0.79 2.98
5 822.2205 5.02 0.04 1.71 5.02 0.82 2.96
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -r 5 -o output.txt
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size blocking stream (unidirectional) test
Test result: "output.txt"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output.txt
# MPI communication test -- Wed Jul 14 16:39:33 2004
# Test mode: Fixed-size stream (unidirectional) test
# Hosts: mk3 <----> mk4
# Blocking communication (MPI_Send/MPI_Recv)
# Total data size of each test (Bytes): 1196425216
# Message size (Bytes): 1048576
# Iteration : 1141
# Test time: 5.000000
# Test repetition: 5
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 1914.6484 5.00 5.00 0.00 5.00 5.00 0.00
2 1914.4683 5.00 5.00 0.00 5.00 5.00 0.00
3 1913.2747 5.00 5.00 0.00 5.00 5.00 0.00
4 1914.4117 5.00 5.00 0.00 5.00 5.00 0.00
5 1914.5514 5.00 5.00 0.00 5.00 5.00 0.00
[mk1 ~/hpcbench/mpi]$
|
Results show that the Myrinet interconnect's throughput is about the
double of that of Gigabit Ethernet.
[ Blocking bidirectional throughput test
] [ TOP ]
The blocking bidirectional throughput test is so called
"ping-pong" test: slave (secondary) node receives a message and sends back
to master node:
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -i -r 6 -o output
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size blocking ping-pong (bidirectional) test
Test result: "output"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output
# MPI communication test -- Wed Jul 14 16:48:46 2004
# Test mode: Fixed-size ping-pong (bidirectional) test
# Hosts: mk3 <----> mk4
# Blocking communication (MPI_Send/MPI_Recv)
# Total data size of each test (Bytes): 254803968
# Message size (Bytes): 1048576
# Iteration : 243
# Test time: 5.000000
# Test repetition: 6
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 817.5592 4.99 0.39 3.12 4.99 0.43 3.16
2 817.5251 4.99 0.33 2.85 4.99 0.42 3.10
3 818.5469 4.98 0.51 2.53 4.98 0.34 3.10
4 818.4082 4.98 0.42 2.41 4.98 0.42 2.94
5 818.6736 4.98 0.43 2.49 4.98 0.45 2.86
6 818.7928 4.98 0.45 2.33 4.98 0.41 3.11
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -ir 6 -o output.txt
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size blocking ping-pong (bidirectional) test
Test result: "output.txt"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output.txt
# MPI communication test -- Wed Jul 14 16:51:39 2004
# Test mode: Fixed-size ping-pong (bidirectional) test
# Hosts: mk3 <----> mk4
# Blocking communication (MPI_Send/MPI_Recv)
# Total data size of each test (Bytes): 597688320
# Message size (Bytes): 1048576
# Iteration : 570
# Test time: 5.000000
# Test repetition: 6
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 1910.7564 5.00 5.00 0.00 5.00 5.01 0.00
2 1912.5686 5.00 5.00 0.00 5.00 5.00 0.00
3 1910.3087 5.01 5.01 0.00 5.01 5.00 0.00
4 1909.9115 5.01 5.00 0.00 5.01 5.01 0.00
5 1912.1223 5.00 5.00 0.00 5.00 5.00 0.00
6 1912.5028 5.00 5.00 0.00 5.00 5.00 0.00
[mk1 ~/hpcbench/mpi]$
|
Results show that the throughputs of ping-pong tests and stream tests are
almost the same.
[ Blocking exponential throughput test
] [ TOP ]
In exponential tests, the message size will increase
exponentially from 1 Byte to a 2^n Bytes, where n is defined by (-e) option.
The following tests define the maximum data size of 64MByte (2^26):
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -e 26 -o output
mk3(Master-node) <--> mk4(Secondary-node)
Exponential blocking stream (unidirectional) test
Test result: "output"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output
# MPI communication test -- Wed Jul 14 16:54:02 2004
# Test mode: Exponential stream (unidirectional) test
# Hosts: mk3 <----> mk4
# Blocking communication (MPI_Send/MPI_Recv)
#
# Message Overall Master-node M-process M-process Slave-node S-process S-process
# Size Throughput Iteration Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Bytes Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 0.0081 10000 9.92 0.00 0.00 9.92 0.01 0.00
2 0.0160 2520 2.52 0.00 0.00 2.52 0.00 0.00
4 0.0317 2499 2.52 0.00 0.00 2.52 0.00 0.00
8 0.0640 2479 2.48 0.00 0.00 2.48 0.00 0.00
16 12.0482 2498 0.03 0.00 0.02 0.03 0.00 0.02
32 24.0612 10000 0.11 0.01 0.04 0.11 0.01 0.09
64 46.9700 10000 0.11 0.01 0.06 0.11 0.03 0.08
128 112.5437 10000 0.09 0.00 0.06 0.09 0.03 0.06
256 197.8421 10000 0.10 0.00 0.01 0.10 0.03 0.07
512 232.4170 10000 0.18 0.01 0.02 0.18 0.03 0.09
1024 251.0281 10000 0.33 0.01 0.00 0.33 0.03 0.13
2048 258.4786 10000 0.63 0.02 0.04 0.63 0.08 0.22
4096 261.9986 10000 1.25 0.01 0.12 1.25 0.13 0.36
8192 264.0463 10000 2.48 0.06 0.09 2.48 0.06 0.52
16384 264.3353 10000 4.96 0.03 0.21 4.96 0.15 0.86
32768 264.7443 5041 4.99 0.03 0.33 4.99 0.10 0.99
65536 259.5392 2524 5.10 0.01 0.39 5.10 0.12 0.82
131072 249.8145 1237 5.19 0.04 0.26 5.19 0.18 1.10
262144 247.5106 595 5.04 0.04 0.29 5.04 0.27 1.15
524288 247.4411 295 5.00 0.02 0.27 5.00 0.25 1.01
1048576 248.6544 147 4.96 0.02 0.18 4.96 0.21 1.00
2097152 244.4746 74 5.08 0.01 0.18 5.08 0.23 1.04
4194304 243.7699 36 4.96 0.04 0.28 4.96 0.25 0.88
8388608 244.1473 18 4.95 0.03 0.34 4.95 0.26 1.32
16777216 243.7410 9 4.96 0.00 0.30 4.96 0.23 1.28
33554432 242.4236 5 5.54 0.07 0.32 5.54 0.30 1.24
67108864 244.1236 5 11.00 0.03 0.61 11.00 0.53 2.58
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -e 26 -o output.txt
mk3(Master-node) <--> mk4(Secondary-node)
Exponential blocking stream (unidirectional) test
Test result: "output.txt"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output.txt
# MPI communication test -- Wed Jul 14 16:58:04 2004
# Test mode: Exponential stream (unidirectional) test
# Hosts: mk3 <----> mk4
# Blocking communication (MPI_Send/MPI_Recv)
#
# Message Overall Master-node M-process M-process Slave-node S-process S-process
# Size Throughput Iteration Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Bytes Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 1.3492 10000 0.06 0.06 0.00 0.06 0.06 0.00
2 2.7097 10000 0.06 0.06 0.00 0.06 0.06 0.00
4 5.4210 10000 0.06 0.06 0.00 0.06 0.06 0.00
8 10.8340 10000 0.06 0.06 0.00 0.06 0.06 0.00
16 21.6515 10000 0.06 0.06 0.00 0.06 0.06 0.00
32 43.2567 10000 0.06 0.05 0.01 0.06 0.06 0.00
64 86.1781 10000 0.06 0.06 0.00 0.06 0.06 0.00
128 161.0577 10000 0.06 0.04 0.01 0.06 0.06 0.00
256 336.5160 10000 0.06 0.06 0.01 0.06 0.06 0.00
512 650.0364 10000 0.06 0.05 0.01 0.06 0.07 0.00
1024 1222.6667 10000 0.07 0.05 0.02 0.07 0.06 0.00
2048 1922.8257 10000 0.09 0.06 0.02 0.09 0.09 0.00
4096 1949.6520 10000 0.17 0.16 0.01 0.17 0.17 0.00
8192 1969.3541 10000 0.33 0.32 0.01 0.33 0.33 0.00
16384 1976.0888 10000 0.66 0.65 0.02 0.66 0.66 0.00
32768 1532.8212 10000 1.71 1.71 0.00 1.71 1.71 0.00
65536 1711.6819 10000 3.06 3.06 0.00 3.06 3.06 0.00
131072 1820.3357 8161 4.70 4.70 0.00 4.70 4.70 0.00
262144 1874.0833 4340 4.86 4.85 0.01 4.86 4.86 0.00
524288 1899.8430 2234 4.93 4.93 0.00 4.93 4.93 0.00
1048576 1912.2904 1132 4.97 4.95 0.00 4.97 4.96 0.00
2097152 1945.7018 569 4.91 4.91 0.00 4.91 4.90 0.00
4194304 1962.1807 289 4.94 4.94 0.00 4.94 4.94 0.00
8388608 1970.1613 146 4.97 4.97 0.01 4.97 4.97 0.01
16777216 1974.6538 73 4.96 4.96 0.00 4.96 4.96 0.00
33554432 1976.3894 36 4.89 4.87 0.01 4.89 4.88 0.01
67108864 1977.6266 18 4.89 4.86 0.02 4.89 4.84 0.03
[mk1 ~/hpcbench/mpi]$
|
The result of GE communication looks unreasonable. The throughputs are
much lower than those of fixed size tests. I couldn't figure out the
problem. I guess there maybe some mechanism (bug?) in MPICH implementation
handling the small size data exchanging and resulting the delay. The
difference of mpitest implementation between fixed-size tests and
exponential tests is that in exponential tests, the program allocates a
memory with maximum test size (64MBytes in this case) for all message size
(2^0 ~2^26) tests. We can see the results of Myrinet test are normal.
[ Non-blocking unidirectional throughput
test ] [ TOP ]
There are a couple of MPI function calls have the concept of
Non-blocking communication. We only test MPI_Isend() and MPI_Irecv() pair:
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -n -r 6 -o output
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size non-blocking stream (unidirectional) test
Test result: "output"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output
# MPI communication test -- Wed Jul 14 18:51:25 2004
# Test mode: Fixed-size stream (unidirectional) test
# Hosts: mk3 <----> mk4
# Non-blocking communication (MPI_Isend/MPI_Irecv)
# Total data size of each test (Bytes): 509607936
# Message size (Bytes): 1048576
# Iteration : 486
# Test time: 5.000000
# Test repetition: 6
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 819.4042 4.98 0.04 1.83 4.98 1.04 2.95
2 819.4323 4.98 0.12 1.66 4.98 1.02 2.76
3 819.4075 4.98 0.08 1.69 4.98 0.86 3.11
4 819.4816 4.97 0.06 1.66 4.98 1.00 3.01
5 818.4036 4.98 0.09 1.71 4.98 0.92 3.09
6 819.4279 4.98 0.07 1.64 4.98 0.97 3.02
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -n -r 6 -o output.txt
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size non-blocking stream (unidirectional) test
Test result: "output.txt"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output.txt
# MPI communication test -- Wed Jul 14 18:54:45 2004
# Test mode: Fixed-size stream (unidirectional) test
# Hosts: mk3 <----> mk4
# Non-blocking communication (MPI_Isend/MPI_Irecv)
# Total data size of each test (Bytes): 1192230912
# Message size (Bytes): 1048576
# Iteration : 1137
# Test time: 5.000000
# Test repetition: 6
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 1911.0491 4.99 4.99 0.00 4.99 4.99 0.00
2 1908.1163 5.00 4.99 0.00 5.00 5.00 0.00
3 1911.2969 4.99 4.99 0.00 4.99 4.99 0.00
4 1910.9985 4.99 4.99 0.00 4.99 4.99 0.00
5 1910.7160 4.99 5.00 0.00 4.99 4.99 0.00
6 1910.9235 4.99 4.99 0.00 4.99 4.99 0.00
[mk1 ~/hpcbench/mpi]$
|
Contrast to blocking unidirectional tests above, there is no big
difference of throughputs between blocking and non-blocking MPI function
calls.
[ Non-blocking bidirectional throughput
test ] [ TOP ]
In non-blocking bidirectional MPI communication, Master node
and slave node keep sending and receiving simultaneously, and MPI_Wait()
function is used for the termination.
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -n -i -r 6 -o output
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size non-blocking ping-pong (bidirectional) test
Test result: "output"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output
# MPI communication test -- Wed Jul 14 18:59:30 2004
# Test mode: Fixed-size ping-pong (bidirectional) test
# Hosts: mk3 <----> mk4
# Non-blocking communication (MPI_Isend/MPI_Irecv)
# Total data size of each test (Bytes): 253755392
# Message size (Bytes): 1048576
# Iteration : 242
# Test time: 5.000000
# Test repetition: 6
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 876.3000 4.63 0.53 2.44 4.63 0.55 3.98
2 876.7293 4.63 0.56 2.27 4.63 0.49 4.02
3 876.2711 4.63 0.51 2.30 4.63 0.54 4.00
4 875.8637 4.64 0.55 2.42 4.64 0.46 4.02
5 876.6733 4.63 0.43 2.25 4.63 0.51 4.00
6 876.2160 4.63 0.47 2.46 4.63 0.51 3.99
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -n -i -r 6 -o output.txt
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size non-blocking ping-pong (bidirectional) test
Test result: "output.txt"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output.txt
# MPI communication test -- Wed Jul 14 19:01:13 2004
# Test mode: Fixed-size ping-pong (bidirectional) test
# Hosts: mk3 <----> mk4
# Non-blocking communication (MPI_Isend/MPI_Irecv)
# Total data size of each test (Bytes): 594542592
# Message size (Bytes): 1048576
# Iteration : 567
# Test time: 5.000000
# Test repetition: 6
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 3776.2298 2.52 2.52 0.00 2.52 2.50 0.00
2 3776.9762 2.52 2.51 0.01 2.52 2.52 0.00
3 3776.4214 2.52 2.52 0.00 2.52 2.52 0.00
4 3772.0101 2.52 2.51 0.00 2.52 2.52 0.00
5 3775.7260 2.52 2.52 0.00 2.52 2.52 0.00
6 3778.5458 2.52 2.52 0.00 2.52 2.52 0.00
[mk1 ~/hpcbench/mpi]$
|
In non-blocking bidirectional MPI tests, Gigabit version increases the
throughput a bit than that of blocking mode, while Myrinet has a double
throughput than its blocking mode.
[ Non-blocking exponential throughput
test ] [ TOP ]
In exponential tests, the message size will increase
exponentially from 1 Byte to a 2^n Bytes, where n is defined by (-e) option.
We will examine bidirectional exponential tests with maximum data size of
64MByte (2^26) in the following examples:
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -in -e 26 -o output
mk3(Master-node) <--> mk4(Secondary-node)
Exponential non-blocking ping-pong (bidirectional) test
Test result: "output"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output
# MPI communication test -- Wed Jul 14 19:08:32 2004
# Test mode: Exponential ping-pong (bidirectional) test
# Hosts: mk3 <----> mk4
# Non-blocking communication (MPI_Isend/MPI_Irecv)
#
# Message Overall Master-node M-process M-process Slave-node S-process S-process
# Size Throughput Iteration Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Bytes Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 0.4059 10000 0.39 0.05 0.11 0.39 0.02 0.12
2 0.8127 10000 0.39 0.04 0.12 0.39 0.04 0.12
4 1.6235 10000 0.39 0.03 0.12 0.39 0.05 0.12
8 3.2465 10000 0.39 0.05 0.10 0.39 0.03 0.16
16 6.1180 10000 0.42 0.05 0.14 0.42 0.06 0.18
32 11.8581 10000 0.43 0.07 0.13 0.43 0.02 0.12
64 23.1937 10000 0.44 0.04 0.16 0.44 0.11 0.12
128 45.0759 10000 0.45 0.00 0.02 0.45 0.03 0.10
256 84.0895 10000 0.49 0.07 0.08 0.49 0.05 0.13
512 154.2349 10000 0.53 0.04 0.19 0.53 0.07 0.16
1024 244.6253 10000 0.67 0.07 0.11 0.67 0.09 0.15
2048 372.3746 10000 0.88 0.05 0.15 0.88 0.04 0.18
4096 652.1813 10000 1.00 0.08 0.57 1.00 0.08 0.50
8192 793.8965 10000 1.65 0.09 0.83 1.65 0.17 0.78
16384 1143.5172 10000 2.29 0.19 1.81 2.29 0.15 1.82
32768 1013.1281 10000 5.17 0.29 3.74 5.18 0.32 3.47
65536 932.4241 4830 5.43 0.34 3.47 5.43 0.39 4.06
131072 885.8682 2223 5.26 0.37 3.35 5.26 0.41 4.08
262144 872.6263 1056 5.08 0.34 3.31 5.08 0.46 4.32
524288 874.1935 520 4.99 0.45 3.17 4.99 0.56 4.25
1048576 878.5305 260 4.97 0.39 3.26 4.97 0.66 4.14
2097152 873.4249 130 4.99 0.48 3.21 4.99 0.47 4.49
4194304 873.2915 65 4.99 0.38 3.33 5.00 0.52 4.46
8388608 873.6141 32 4.92 0.38 3.08 4.92 0.45 4.44
16777216 874.1411 16 4.91 0.37 3.06 4.91 0.62 4.30
33554432 874.0057 8 4.91 0.37 2.97 4.91 0.53 4.37
67108864 868.5910 5 6.18 0.42 3.85 6.18 0.64 5.52
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -ine 26 -o output.txt
mk3(Master-node) <--> mk4(Secondary-node)
Exponential non-blocking ping-pong (bidirectional) test
Test result: "output.txt"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output.txt
# MPI communication test -- Wed Jul 14 19:17:54 2004
# Test mode: Exponential ping-pong (bidirectional) test
# Hosts: mk3 <----> mk4
# Non-blocking communication (MPI_Isend/MPI_Irecv)
#
# Message Overall Master-node M-process M-process Slave-node S-process S-process
# Size Throughput Iteration Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Bytes Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 1.6293 10000 0.10 0.10 0.00 0.10 0.09 0.00
2 3.2537 10000 0.10 0.10 0.00 0.10 0.10 0.00
4 6.4752 10000 0.10 0.10 0.00 0.10 0.10 0.00
8 13.0232 10000 0.10 0.10 0.00 0.10 0.10 0.00
16 25.7786 10000 0.10 0.10 0.00 0.10 0.10 0.00
32 51.1105 10000 0.10 0.10 0.00 0.10 0.10 0.00
64 100.3291 10000 0.10 0.10 0.00 0.10 0.10 0.00
128 187.9520 10000 0.11 0.11 0.00 0.11 0.11 0.00
256 311.8096 10000 0.13 0.13 0.00 0.13 0.13 0.00
512 547.8572 10000 0.15 0.15 0.00 0.15 0.15 0.00
1024 850.1319 10000 0.19 0.19 0.00 0.19 0.19 0.00
2048 1282.9666 10000 0.26 0.26 0.00 0.26 0.26 0.00
4096 1694.9692 10000 0.39 0.39 0.00 0.39 0.39 0.00
8192 2268.3214 10000 0.58 0.57 0.00 0.58 0.57 0.00
16384 2585.6188 10000 1.01 1.02 0.00 1.01 1.02 0.00
32768 2860.4786 10000 1.83 1.83 0.00 1.83 1.83 0.00
65536 3290.2138 10000 3.19 3.19 0.00 3.19 3.19 0.00
131072 3540.9363 7844 4.65 4.64 0.00 4.65 4.64 0.00
262144 3677.4967 4221 4.81 4.82 0.00 4.81 4.82 0.00
524288 3733.4466 2191 4.92 4.90 0.00 4.92 4.92 0.00
1048576 3775.4940 1112 4.94 4.95 0.00 4.94 4.94 0.00
2097152 3845.2595 562 4.90 4.90 0.00 4.90 4.91 0.00
4194304 3876.0652 286 4.95 4.94 0.00 4.95 4.95 0.00
8388608 3888.2378 144 4.97 4.96 0.01 4.97 4.96 0.00
16777216 3080.4510 72 6.27 6.26 0.02 6.27 6.26 0.01
33554432 3050.5405 28 4.93 4.89 0.03 4.93 4.90 0.03
67108864 3073.8384 14 4.89 4.85 0.04 4.89 4.82 0.06
[mk1 ~/hpcbench/mpi]$
|
[ Test with system
log ] [
TOP ]
Currently the system resource tracing functionality is only
available for Linux boxes. To enable the system logging, you should enable
the write option (-o) and CPU logging option (-c). In the following example,
the file "output" records the results of tests, "ouput.m_log" logs master
node's system information, "output.s_log" logs slave (secondary) node's
system information. System logs have two more entries than test repetition,
the first one showing pre-test system information and the last one showing
system's post-test information.
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -r 5 -co output
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size blocking stream (unidirectional) test
Message-size: 1048576 Bytes iteration: 490 test-time: 5.000000 Seconds
(1) Throughput(Mbps): 817.6352 Message-size(Bytes): 1048576 Test-time: 5.03
(2) Throughput(Mbps): 819.4548 Message-size(Bytes): 1048576 Test-time: 5.02
(3) Throughput(Mbps): 819.4652 Message-size(Bytes): 1048576 Test-time: 5.02
(4) Throughput(Mbps): 819.4164 Message-size(Bytes): 1048576 Test-time: 5.02
(5) Throughput(Mbps): 819.4528 Message-size(Bytes): 1048576 Test-time: 5.02
Test result: "output"
Secondary node's syslog: "output.s_log"
Master node's syslog: "output.m_log"
Test done!
[mk1 ~/hpcbench/mpi]$ cat output
# MPI communication test -- Wed Jul 14 20:10:55 2004
# Test mode: Fixed-size stream (unidirectional) test
# Hosts: mk3 <----> mk4
# Blocking communication (MPI_Send/MPI_Recv)
# Total data size of each test (Bytes): 513802240
# Message size (Bytes): 1048576
# Iteration : 490
# Test time: 5.000000
# Test repetition: 5
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 817.6352 5.03 0.05 1.84 5.03 0.88 3.06
2 819.4548 5.02 0.09 1.71 5.02 0.81 3.04
3 819.4652 5.02 0.08 1.81 5.02 0.83 3.18
4 819.4164 5.02 0.03 1.64 5.02 0.83 3.11
5 819.4528 5.02 0.08 1.74 5.02 0.90 2.90
[mk1 ~/hpcbench/mpi]$ cat output.m_log
# mk3 syslog -- Wed Jul 14 20:10:55 2004
# Watch times: 7
# Network devices (interface): 2 ( loop eth0 )
# CPU number: 4
##### System info, statistics of network interface <loop> and its interrupts to each CPU #####
# CPU(%) Mem(%) Interrupt Page Swap Context <loop> information
# Load User Sys Usage Overall In/out In/out Swtich RecvPkg RecvByte SentPkg SentByte Int-CPU0 Int-CPU1 Int-CPU2 Int-CPU3
0 0 0 0 12 175 24 0 104 0 0 0 0 0 0 0 0
1 18 0 18 12 181172 16 0 91453 0 0 0 0 0 0 0 0
2 14 0 13 12 181996 64 0 90028 0 0 0 0 0 0 0 0
3 15 0 14 12 181872 16 0 89691 0 0 0 0 0 0 0 0
4 14 0 14 12 181886 16 0 89903 0 0 0 0 0 0 0 0
5 14 0 14 12 181996 16 0 89858 0 0 0 0 0 0 0 0
6 0 0 0 12 172 0 0 104 0 0 0 0 0 0 0 0
##### System info, statistics of network interface <eth0> and its interrupts to each CPU #####
# CPU(%) Mem(%) Interrupt Page Swap Context <eth0> information
# Load User Sys Usage Overall In/out In/out Swtich RecvPkg RecvByte SentPkg SentByte Int-CPU0 Int-CPU1 Int-CPU2 Int-CPU3
0 0 0 0 12 175 24 0 104 114 31262 135 35056 51 0 0 0
1 18 0 18 12 181172 16 0 91453 194432 14712281 387683 586438922 180568 0 0 0
2 14 0 13 12 181996 64 0 90028 171696 12064155 343253 519623902 181392 0 0 0
3 15 0 14 12 181872 16 0 89691 172493 12118663 344843 522033042 181295 0 0 0
4 14 0 14 12 181886 16 0 89903 171803 12072089 343458 520026646 181288 0 0 0
5 14 0 14 12 181996 16 0 89858 171785 12069006 343450 519975620 181385 0 0 0
6 0 0 0 12 172 0 0 104 28902 2031079 57721 87384210 55 0 0 0
## CPU workload distribution:
##
## CPU0 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 1.0 0.0 1.0 99.0 0.2 0.0 0.2 99.8
1 49.1 0.4 48.7 50.9 18.4 0.2 18.1 81.6
2 56.7 1.8 54.9 43.3 14.2 0.4 13.7 85.8
3 60.4 1.6 58.8 39.6 15.2 0.4 14.8 84.8
4 58.6 0.6 58.1 41.4 14.7 0.1 14.5 85.3
5 59.6 1.6 58.1 40.4 14.9 0.4 14.5 85.1
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU1 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
1 0.0 0.0 0.0 100.0 18.4 0.2 18.1 81.6
2 0.0 0.0 0.0 100.0 14.2 0.4 13.7 85.8
3 0.0 0.0 0.0 100.0 15.2 0.4 14.8 84.8
4 0.0 0.0 0.0 100.0 14.7 0.1 14.5 85.3
5 0.0 0.0 0.0 100.0 14.9 0.4 14.5 85.1
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU2 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
1 0.0 0.0 0.0 100.0 18.4 0.2 18.1 81.6
2 0.0 0.0 0.0 100.0 14.2 0.4 13.7 85.8
3 0.2 0.0 0.2 99.8 15.2 0.4 14.8 84.8
4 0.0 0.0 0.0 100.0 14.7 0.1 14.5 85.3
5 0.0 0.0 0.0 100.0 14.9 0.4 14.5 85.1
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU3 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
1 24.4 0.6 23.8 75.6 18.4 0.2 18.1 81.6
2 0.0 0.0 0.0 100.0 14.2 0.4 13.7 85.8
3 0.2 0.0 0.2 99.8 15.2 0.4 14.8 84.8
4 0.0 0.0 0.0 100.0 14.7 0.1 14.5 85.3
5 0.0 0.0 0.0 100.0 14.9 0.4 14.5 85.1
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
[mk1 ~/hpcbench/mpi]$ cat output.s_log
# mk4 syslog -- Wed Jul 14 20:09:59 2004
# Watch times: 7
# Network devices (interface): 2 ( loop eth0 )
# CPU number: 4
##### System info, statistics of network interface <loop> and its interrupts to each CPU #####
# CPU(%) Mem(%) Interrupt Page Swap Context <loop> information
# Load User Sys Usage Overall In/out In/out Swtich RecvPkg RecvByte SentPkg SentByte Int-CPU0 Int-CPU1 Int-CPU2 Int-CPU3
0 0 0 0 10 197 0 0 124 0 0 0 0 0 0 0 0
1 38 4 33 11 339496 24 0 505587 0 0 0 0 0 0 0 0
2 37 4 33 11 340876 16 0 508579 0 0 0 0 0 0 0 0
3 38 4 34 11 341520 16 0 507959 0 0 0 0 0 0 0 0
4 37 4 33 11 341452 16 0 510991 0 0 0 0 0 0 0 0
5 37 4 33 11 341590 16 0 510688 0 0 0 0 0 0 0 0
6 0 0 0 11 194 0 0 124 0 0 0 0 0 0 0 0
##### System info, statistics of network interface <eth0> and its interrupts to each CPU #####
# CPU(%) Mem(%) Interrupt Page Swap Context <eth0> information
# Load User Sys Usage Overall In/out In/out Swtich RecvPkg RecvByte SentPkg SentByte Int-CPU0 Int-CPU1 Int-CPU2 Int-CPU3
0 0 0 0 10 197 0 0 124 140 39002 141 34492 52 0 0 0
1 38 4 33 11 339496 24 0 505587 390093 590152444 195707 14799182 338843 0 0 0
2 37 4 33 11 340876 16 0 508579 343136 519496213 171651 12059178 340231 0 0 0
3 38 4 34 11 341520 16 0 507959 344903 522102320 172491 12117566 340862 0 0 0
4 37 4 33 11 341452 16 0 510991 343470 520085567 171836 12072898 340819 0 0 0
5 37 4 33 11 341590 16 0 510688 343460 519928360 171810 12070238 340942 0 0 0
6 0 0 0 11 194 0 0 124 55319 83722883 27656 1943130 53 0 0 0
## CPU workload distribution:
##
## CPU0 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
1 73.5 0.0 73.5 26.5 38.2 4.4 33.8 61.8
2 73.1 0.0 73.1 26.9 37.6 4.2 33.4 62.4
3 72.8 0.0 72.8 27.2 38.1 4.1 34.0 61.9
4 70.7 0.0 70.7 29.3 37.2 4.1 33.1 62.8
5 75.2 0.0 75.2 24.8 37.6 4.5 33.2 62.4
6 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
## CPU1 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 1.0 0.0 1.0 99.0 0.2 0.0 0.2 99.8
1 1.0 0.2 0.8 99.0 38.2 4.4 33.8 61.8
2 1.0 0.6 0.4 99.0 37.6 4.2 33.4 62.4
3 0.2 0.0 0.2 99.8 38.1 4.1 34.0 61.9
4 0.0 0.0 0.0 100.0 37.2 4.1 33.1 62.8
5 0.0 0.0 0.0 100.0 37.6 4.5 33.2 62.4
6 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
## CPU2 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
1 78.2 17.4 60.8 21.8 38.2 4.4 33.8 61.8
2 76.2 16.0 60.2 23.8 37.6 4.2 33.4 62.4
3 79.6 16.5 63.1 20.4 38.1 4.1 34.0 61.9
4 78.0 16.4 61.6 22.0 37.2 4.1 33.1 62.8
5 75.4 17.9 57.5 24.6 37.6 4.5 33.2 62.4
6 1.0 0.0 1.0 99.0 0.2 0.0 0.2 99.8
## CPU3 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
1 0.0 0.0 0.0 100.0 38.2 4.4 33.8 61.8
2 0.0 0.0 0.0 100.0 37.6 4.2 33.4 62.4
3 0.0 0.0 0.0 100.0 38.1 4.1 34.0 61.9
4 0.0 0.0 0.0 100.0 37.2 4.1 33.1 62.8
5 0.0 0.0 0.0 100.0 37.6 4.5 33.2 62.4
6 0.0 0.0 0.0 100.0 0.2 0.0 0.2 99.8
[mk1 ~/hpcbench/mpi]$
|
In the GE blocking stream MPI tests, master nodes has about 15% CPU
usage and mainly consumes CPU0 system time, while slave (secondary) node
has about 37% CPU usage and distributes workload to CPU0 and CPU2. Let's
examine Myrinet interconnect:
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -r 5 -co output.txt
mk3(Master-node) <--> mk4(Secondary-node)
Fixed-size blocking stream (unidirectional) test
Message-size: 1048576 Bytes iteration: 1138 test-time: 5.000000 Seconds
(1) Throughput(Mbps): 1914.4257 Message-size(Bytes): 1048576 Test-time: 4.99
(2) Throughput(Mbps): 1914.5681 Message-size(Bytes): 1048576 Test-time: 4.99
(3) Throughput(Mbps): 1914.1915 Message-size(Bytes): 1048576 Test-time: 4.99
(4) Throughput(Mbps): 1914.5889 Message-size(Bytes): 1048576 Test-time: 4.99
(5) Throughput(Mbps): 1914.4461 Message-size(Bytes): 1048576 Test-time: 4.99
Test result: "output.txt"
Master node's syslog: "output.txt.m_log"
Test done!
Secondary node's syslog: "output.txt.s_log"
[mk1 ~/hpcbench/mpi]$ cat output.txt
# MPI communication test -- Wed Jul 14 20:20:44 2004
# Test mode: Fixed-size stream (unidirectional) test
# Hosts: mk3 <----> mk4
# Blocking communication (MPI_Send/MPI_Recv)
# Total data size of each test (Bytes): 1193279488
# Message size (Bytes): 1048576
# Iteration : 1138
# Test time: 5.000000
# Test repetition: 5
#
# Overall Master-node M-process M-process Slave-node S-process S-process
# Throughput Elapsed-time User-mode Sys-mode Elapsed-time User-mode Sys-mode
# Mbps Seconds Seconds Seconds Seconds Seconds Seconds
1 1914.4257 4.99 4.98 0.00 4.99 4.99 0.00
2 1914.5681 4.99 4.98 0.00 4.99 4.99 0.00
3 1914.1915 4.99 4.98 0.00 4.99 4.99 0.00
4 1914.5889 4.99 4.98 0.00 4.99 5.00 0.00
5 1914.4461 4.99 4.98 0.00 4.99 4.99 0.00
[mk1 ~/hpcbench/mpi]$ cat output.txt.m_log
# mk3 syslog -- Wed Jul 14 20:20:44 2004
# Watch times: 7
# Network devices (interface): 2 ( loop eth0 )
# CPU number: 4
##### System info, statistics of network interface <loop> and its interrupts to each CPU #####
# CPU(%) Mem(%) Interrupt Page Swap Context <loop> information
# Load User Sys Usage Overall In/out In/out Swtich RecvPkg RecvByte SentPkg SentByte Int-CPU0 Int-CPU1 Int-CPU2 Int-CPU3
0 0 0 0 14 180 0 0 106 0 0 0 0 0 0 0 0
1 24 24 0 14 827 16 0 455 0 0 0 0 0 0 0 0
2 24 24 0 14 851 16 0 493 0 0 0 0 0 0 0 0
3 24 24 0 14 884 16 0 527 0 0 0 0 0 0 0 0
4 25 24 0 14 876 16 0 521 0 0 0 0 0 0 0 0
5 24 24 0 14 885 16 0 537 0 0 0 0 0 0 0 0
6 0 0 0 14 177 0 0 104 0 0 0 0 0 0 0 0
##### System info, statistics of network interface <eth0> and its interrupts to each CPU #####
# CPU(%) Mem(%) Interrupt Page Swap Context <eth0> information
# Load User Sys Usage Overall In/out In/out Swtich RecvPkg RecvByte SentPkg SentByte Int-CPU0 Int-CPU1 Int-CPU2 Int-CPU3
0 0 0 0 14 180 0 0 106 27 3633 30 3360 51 0 0 0
1 24 24 0 14 827 16 0 455 100 13491 106 12428 237 0 0 0
2 24 24 0 14 851 16 0 493 99 13427 106 12428 249 0 0 0
3 24 24 0 14 884 16 0 527 99 13427 106 12428 248 0 0 0
4 25 24 0 14 876 16 0 521 83 11162 88 10352 250 0 0 0
5 24 24 0 14 885 16 0 537 96 13235 106 12428 244 0 0 0
6 0 0 0 14 177 0 0 104 26 3547 28 4520 51 0 0 0
## CPU workload distribution:
##
## CPU0 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
1 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
2 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
3 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
4 0.2 0.0 0.2 99.8 25.0 24.9 0.1 75.0
5 0.0 0.0 0.0 100.0 24.9 24.9 0.1 75.0
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU1 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
1 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
2 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
3 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
4 0.0 0.0 0.0 100.0 25.0 24.9 0.1 75.0
5 0.0 0.0 0.0 100.0 24.9 24.9 0.1 75.0
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU2 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
1 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
2 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
3 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.1
4 0.0 0.0 0.0 100.0 25.0 24.9 0.1 75.0
5 0.2 0.0 0.2 99.8 24.9 24.9 0.1 75.0
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU3 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
1 99.6 99.6 0.0 0.4 24.9 24.9 0.0 75.1
2 99.6 99.6 0.0 0.4 24.9 24.9 0.0 75.1
3 99.4 99.4 0.0 0.6 24.9 24.9 0.0 75.1
4 99.8 99.6 0.2 0.2 25.0 24.9 0.1 75.0
5 99.6 99.6 0.0 0.4 24.9 24.9 0.1 75.0
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
[mk1 ~/hpcbench/mpi]$ cat output.txt.s_log
# mk4 syslog -- Wed Jul 14 20:19:47 2004
# Watch times: 7
# Network devices (interface): 2 ( loop eth0 )
# CPU number: 4
##### System info, statistics of network interface <loop> and its interrupts to each CPU #####
# CPU(%) Mem(%) Interrupt Page Swap Context <loop> information
# Load User Sys Usage Overall In/out In/out Swtich RecvPkg RecvByte SentPkg SentByte Int-CPU0 Int-CPU1 Int-CPU2 Int-CPU3
0 0 0 0 12 191 40 0 126 0 0 0 0 0 0 0 0
1 24 24 0 12 951 16 0 580 0 0 0 0 0 0 0 0
2 24 24 0 12 961 16 0 600 0 0 0 0 0 0 0 0
3 24 24 0 12 953 16 0 590 0 0 0 0 0 0 0 0
4 25 24 0 12 925 16 0 562 0 0 0 0 0 0 0 0
5 25 24 0 12 928 16 0 556 0 0 0 0 0 0 0 0
6 0 0 0 12 198 0 0 122 0 0 0 0 0 0 0 0
##### System info, statistics of network interface <eth0> and its interrupts to each CPU #####
# CPU(%) Mem(%) Interrupt Page Swap Context <eth0> information
# Load User Sys Usage Overall In/out In/out Swtich RecvPkg RecvByte SentPkg SentByte Int-CPU0 Int-CPU1 Int-CPU2 Int-CPU3
0 0 0 0 12 191 40 0 126 27 3633 30 3360 51 0 0 0
1 24 24 0 12 951 16 0 580 99 13421 105 12230 249 0 0 0
2 24 24 0 12 961 16 0 600 98 13357 105 12230 248 0 0 0
3 24 24 0 12 953 16 0 590 79 10724 84 9784 245 0 0 0
4 25 24 0 12 925 16 0 562 99 13421 105 12230 247 0 0 0
5 25 24 0 12 928 16 0 556 95 13165 105 12230 242 0 0 0
6 0 0 0 12 198 0 0 122 21 2761 21 2446 52 0 0 0
## CPU workload distribution:
##
## CPU0 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
1 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
2 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
3 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
4 0.0 0.0 0.0 100.0 25.0 25.0 0.0 75.0
5 0.2 0.0 0.2 99.8 25.1 24.9 0.1 75.0
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU1 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
1 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
2 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
3 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
4 0.2 0.0 0.2 99.8 25.0 25.0 0.0 75.0
5 0.0 0.0 0.0 100.0 25.1 24.9 0.1 75.0
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU2 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
1 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
2 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
3 0.0 0.0 0.0 100.0 24.9 24.9 0.0 75.0
4 0.0 0.0 0.0 100.0 25.0 25.0 0.0 75.0
5 0.2 0.0 0.2 99.8 25.1 24.9 0.1 75.0
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
## CPU3 workload (%) Overall CPU workload (%)
# < load user system idle > < load user system idle >
0 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
1 99.8 99.8 0.0 0.2 24.9 24.9 0.0 75.0
2 99.8 99.8 0.0 0.2 24.9 24.9 0.0 75.0
3 99.8 99.8 0.0 0.2 24.9 24.9 0.0 75.0
4 99.8 99.8 0.0 0.2 25.0 25.0 0.0 75.0
5 99.8 99.8 0.0 0.2 25.1 24.9 0.1 75.0
6 0.0 0.0 0.0 100.0 0.0 0.0 0.0 100.0
[mk1 ~/hpcbench/mpi]$
|
Wow, with Myrinet communications, the master node and slave (secondary)
node's CPU usages are almost the same! Both are exclusively occupying CPU3's
clock cycles, and all process time is spent in user mode. NO system calls in
Myrinet communications! Is it the power of Zero-copy technique?
[ Latency
(Roundtrip time) test ] [
TOP ]
This test is like a MPI version of "ping". We test MPI
roundtrip time with default messge size (64Bytes) and 1KBytes data:
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -a -r 5
mk3(Master-node) <--> mk4(Secondary-node)
MPI communicaiton Round Trip Time (latency) test
MPI Round Trip Time (1) : 72.694 usec
MPI Round Trip Time (2) : 72.716 usec
MPI Round Trip Time (3) : 72.763 usec
MPI Round Trip Time (4) : 72.541 usec
MPI Round Trip Time (5) : 72.749 usec
Message size (Bytes) : 64
MPI RTT min/avg/max = 72.541/72.693/72.763 usec
Test done!
[mk1 ~/hpcbench/mpi]$ ge-mpirun -np 2 -machinefile machine-file ge-mpitest -A 1k -r 5
mk3(Master-node) <--> mk4(Secondary-node)
MPI communicaiton Round Trip Time (latency) test
MPI Round Trip Time (1) : 124.785 usec
MPI Round Trip Time (2) : 124.601 usec
MPI Round Trip Time (3) : 124.611 usec
MPI Round Trip Time (4) : 124.756 usec
MPI Round Trip Time (5) : 124.623 usec
Message size (Bytes) : 1024
MPI RTT min/avg/max = 124.601/124.675/124.785 usec
Test done!
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -a -r 5
mk3(Master-node) <--> mk4(Secondary-node)
MPI communicaiton Round Trip Time (latency) test
MPI Round Trip Time (1) : 14.247 usec
MPI Round Trip Time (2) : 14.245 usec
MPI Round Trip Time (3) : 14.243 usec
MPI Round Trip Time (4) : 14.245 usec
MPI Round Trip Time (5) : 14.255 usec
Message size (Bytes) : 64
MPI RTT min/avg/max = 14.243/14.247/14.255 usec
Test done!
[mk1 ~/hpcbench/mpi]$ mpirun -np 2 -machinefile machine-file mpitest -A 1k -r 5
mk3(Master-node) <--> mk4(Secondary-node)
MPI communicaiton Round Trip Time (latency) test
MPI Round Trip Time (1) : 32.261 usec
MPI Round Trip Time (2) : 32.312 usec
MPI Round Trip Time (3) : 32.328 usec
MPI Round Trip Time (4) : 32.261 usec
MPI Round Trip Time (5) : 32.246 usec
Message size (Bytes) : 1024
MPI RTT min/avg/max = 32.246/32.282/32.328 usec
Test done!
[mk1 ~/hpcbench/mpi]$
|
[ Plot data
] [ TOP
]
If write option (-o) and plot option (-P) are both defined,
a configuration file for plotting with format of "ouput.plot" will be
created. Use gnuplot to plot the data or create the postscript files of the
plotting:
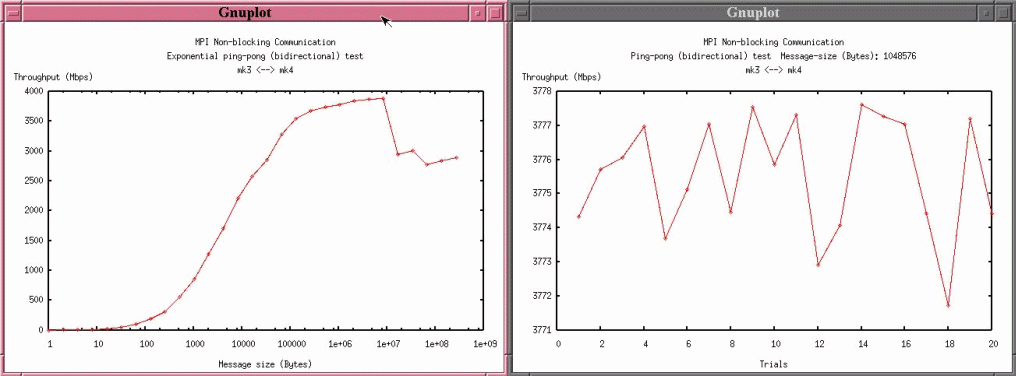
|
